What is a tall poppy among web pages?
Glen Pringle, Lloyd Allison and David L. D owe, Proc. 7th Int. World Wide Web Conference, Brisbane, pp.369-377, & Comp. Networks & ISDN Systems 30(#1-7), April 1998
Abstract: Search engines and indexes were created to help people find information amongst the rapidly increasing number of world wide web (WWW) pages. The search engines automatically visit and index pages so that they can return good matches for their users' queries. The way that this indexing is done varies from engine to engine and the detail is usually secret although the strategy is sometimes made public in general terms. The search engines' aim is to return relevant pages quickly. On the other hand, the author of a web page has a vested interest in it rating highly, for appropriate queries, on as many search engines as possible. Some authors have an interest in their page rating well for a great many types of query indeed - spamming has come to the web.
We treat modelling the workings of WWW search engines as an inductive inference problem. A training set of data is collected, being pages returned in response to typical queries. Decision trees are used as the model class for the search engines' selection criteria although this is not to say that search engines actually contain decision trees. A machine learning program is used to infer a decision tree for each search engine, an information-theory criterion being used to direct the inference and to prevent over-fitting.
Keywords: Search Engines, Machine Learning
1 Introduction
It is impossible to estimate accurately the number of world wide web (WWW) pages but there are truly a great many and this makes finding relevant information surprisingly difficult. Indexes such as Yahoo and search engines were created to help with this task. In this paper, models are built of the way in which popular search engines select pages to be returned as good matches for their users' queries. Such a model gives a kind of explanation of the inner workings of a search engine.
Search engines traverse WWW sites, fetching pages and analysing them to build indexes. When a user enters a query at a search engine, the engine uses its index to return a list of pages in what it considers to be decreasing order of relevance to the query. Relevance is a subjective notion and different engines give different responses to a query because they keep different information and weight it differently or, of course, because they have indexed different sections of the WWW.
The author of a WWW page wants it to be found by interested readers, i.e. wants it to be returned, preferably high in an engine's rankings, if the page is relevant to a query. In an ideal world, the author's, the reader's and the search engine's notions of relevance coincide.
An author may have an over-inclusive idea of the relevance of her or his page, particularly if actively promoting something, be it a thesis or a product. Some authors want their pages to be highly ranked for many or even most queries and they attempt to distort the search engines' indexing and ranking processes to this end; this is just the most recent version of "spamming". In response, search engines warn against the practice and state that steps are being taken to prevent it. These steps are rarely spelled out, for if they were the "game" would simply shift to the more subtle level of trying to circumvent them.
Academics cannot pretend to be above being interested in the ranking of WWW pages (unless they have no interest at all in the WWW either as a reader or as an author) because there seems to be hardly a topic remaining where a search engine will not report tens or hundreds of thousands of matches and return a maximum-length list of "relevant" pages. For even the most obscure topics there are companies trying to attract the searcher's attention.
We infer models of the workings of various popular WWW search engines. The model class is that of decision trees [Quinlan89, Wallace93]. This is not to claim that any search engine contains a decision tree within it. Decision trees are also used in the field of expert systems to infer and explain the actions of human experts, which is not to say that they contain decision trees either. Rather decision trees are a very general model for decision processes and can approximate a great many types of such processes. In addition, a decision tree can be inspected and understood in a natural way so that it forms a certain kind of explanation of, in this case, a search engine. Rules can be drawn from the tree which should be followed if you want your web pages to be returned by a WWW search engine.
There are various studies of and guides to the behaviour of search engines, some on the WWW at commercial sites, e.g. Sullivan and Northern Webs. These are useful guides but they are informal and based on personal experience, surveys or limited test cases. The topic of `Search Engine Secrets' is also a popular one for the scourge of junk e-mail: all will be revealed for $49.95. In contrast, our results are objective, based on large data sets, and use a consistent model class across the search engines, one that can be understood as an explanation.
The search engines studied to date are Alta Vista, Excite, Infoseek and Lycos. The data gathering process, the models inferred for the search engines and their analysis are described in the following sections.
2 The Problem
The problem is to understand and explain why a WWW search engine returns certain pages, and not other pages, in response to a query. We consider a page being returned as a "positive" and its not being returned as a "negative". It would obviously be nice also to explain the rankings within the positives but as a first step we only consider the simpler selection decision. An engine will return "relevant" pages up to some limit, typically about 200 pages.
3 Data
The data for an inference problem needs to contain positive and negative examples. Here, the positives should be pages returned by a search engine in response to "typical" queries. Fortunately Magellan offers a "voyeur" page which displays the terms currently being searched for at that site. A program was written to sample these terms over a period of some weeks, collecting a list of 60,000 searches. The 50 words below were randomly selected from the list:
arbetsf, autotrader, backpacking, bodybuilding, cars, chattropolis, dating, desassambler, dish, erotica, erotique, espnet, fonderie, gabba, games, godwind, haiti, heath, hustler, hydrography, intercession, ireland, journaux, languages, leukemia, magic, metacrawler, modem, nasa, palsy, poultry, proteus, puch, refrigerator, sailing, screensavers, seagate, sex, shemale, simpsom, snowheights, soccer, soundcard, terengganu, tesl, vasectomy, virus, wallpaper, wordperfect, zilkha.
Multi-word searches were ignored when making the selection but may be considered in future work. A frequently used search term had a greater chance of being selected. No attempt was made to correct spelling, which would in any case be fraught with difficulty. It is possible, but unlikely, that searches at Magellan are atypical of WWW searches in general. As an aside, searches to do with sex form a significant fraction of the list but are definitely in the minority; it is hard to know whether to be worried or relieved.
The 50 selected words were used as queries on all the search engines. Up to 200 pages were obtained in this way for each engine and each query, i.e. up to 10,000 pages per engine.
Ideally, negative examples would be random, non-returned pages known to the search engine in question but it is not possible to get these data. Instead pages, equal in number to the positives, were selected at random from the returns to other queries to act as the negative examples for a given query. This gives up to 10,000 positive and 10,000 negative examples for each search engine.
4 The Form of the Analysis
A search engine selects pages in response to a query using some function of some attributes of the page and the query word. Perhaps the attribute most likely apriori to be significant is the number of occurrences of the word in the document. Pages are written in hyper text markup language (HTML) which gives a structure to them and it was clear that at least some search engines took notice of this structure. The HTML source of many pages was inspected, including some pages with quite unusual characteristics, evidently attempts at spamming in order to rate highly. It was considered that the following attributes of a page might be relevant to some or all of the search engines:
- Number of times the keyword occurs in the URL.
- Number of times the keyword occurs in the document title.
- Number of words in the document title
- Number of times the keyword occurs in meta fields - typically keyword list and description.
- Number of times keyword occurs in the first heading tag <H?>.
- Number of words in the first heading tag.
- Total number of times the keyword occurs in the document including title, meta, etc.
- Length of the document.
The data set for a search engine consists of up to 20,000 items representing pages, each item having 9 fields - the 8 attributes above plus a 9th indicating whether the item is a positive or a negative example.
A decision tree was inferred from this data for each search engine. Such a tree consists of internal, test nodes and of leaf nodes. A test node contains a test on the value of one of the 8 attributes above. An item therefore passes down the tree to some leaf according to its particular attribute values. The question of what is a good decision tree is decided on information-theoretic grounds, i.e. how efficiently the tree can be used to encode the search engine's decisions. A good tree will tend to have high purity in its leaf nodes - mostly positive or mostly negative items. It is important that the cost of the tree itself be included in the information calculations as this prevents over-fitting. All other things being equal, a simple tree is preferred to a complex one. Such a measure for decision trees was proposed by Quinlan [Quinlan93] and improved by Wallace and Patrick [Wallace93] using the minimum message length framework (MML); we use the program of the latter authors.
One potential advantage of decision tree inference is its ability, in the limit of increasing data, to converge arbitrarily closely to any underlying model.
As an inference technique, MML has the merits of being resistant to and robust from learning noise in the data, such as can occur when a recently analysed WWW page has since been removed or re-located and now returns a "File Not Found".
MML has the additional advantage of not just being interested in "Right / Wrong" prediction, but also of being interested in probabilistic prediction. One benefit of the MML inference technique is that the predicted probabilities are near optimal (in the sense that they come close to minimising the expected Kullback-Leibler distance). So, when leaf nodes are returned with various relative frequencies in the positive and negative categories, these can be taken not only as fairly reliable indicators of which category but also as fairly reliable predictors of the probability of being in that category.
5 Cheating
There are various ways in which the author of a WWW page can attempt to influence or trick a search engine. The simplest is the excessive repetition of one or more keywords. This can be hidden from the casual reader by placing it in the head section of the page or by using an invisible font, e.g. one that is the same colour as the background of the page. Such pages do appear in the data sets, and this is as it should be because the search engines' responses to them are of interest.
Another method of cheating is for a web server to deliver a special page to a WWW search engine that is doing indexing; this is possible because well-behaved engines and robots announce their identities. The search engine's notion of relevance is then based on false pretences. There is no way of detecting the practice in this study. It has to be hoped that it is rare and forms a small part of the noise in our inference problem. (The only defence open to a search engine seems to be random checks on pages at suspect sites, carried out by an anonymous computer a little time after indexing.)
6 Lycos
The best decision tree for the Lycos search engine is shown in Figure 1. The root node is a test on the total number of matches on the keyword, indicating that this is indeed the most important attribute, as it is for the other search engines. Items with less than 0.5 matches (i.e. no matches) pass into the left subtree. This corresponds mostly (over 8,000) to negatives but also to 3,500 positives. The latter are explained away as various incarnations of "page not found", "this page has moved", "there has been a reorganization" and the like, because not all web servers return these as errors. The left subtree amounts to a dissection of these various kinds of messages and is not interesting for our purposes. For purposes of space it has been been omitted from the figure.
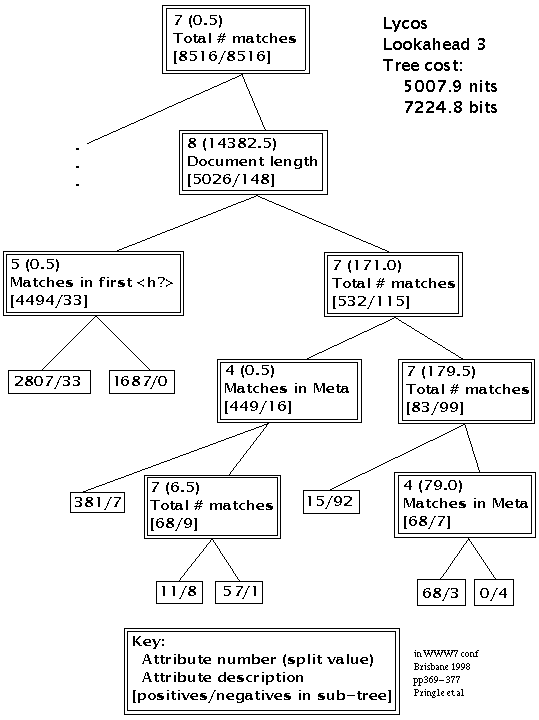
Figure 1: Decision Tree for Lycos
The right subtree corresponds to pages with at least one match on the keyword. The next test is to compare the document length to 14K. (Note the decision tree program places such splits between two of the actual values seen for this attribute, so there is no great significance in the precise value which is data dependent.) Shorter documents are mostly positives (4494+:33-), while longer documents contain a greater fraction of negatives (532+:115-). This suggests a slight bias against long documents. Any bias is probably not deliberate but may be the result of the way that authors write and the way that search engines (may) weight word frequencies. As a document on some topic grows in length, it is natural to use relevant words more often, but not in direct proportion to document length; one tends to use alternative words, pronouns and other ways of referring to the topic. The search engine is very likely to count the number of appearances of the keyword but is also likely to discount it against document length in some way. The combination of these two factors probably explains the slightly lower positive rate for documents over 14K in length.
The subtree right-left (RL) next tests for matches in the first heading. It is better to have such a match (1687+:0-) than not (2807+:33-).
The subtree RR of long documents, compares the number of matches to the large value 171. It is better to be below this level (449+:16-) than above it (83+:99-). This is surprising at first glance but probably indicates that Lycos is taking some kind of anti-spamming measures. It should not be thought that Lycos actually tests for more than 171 matches but rather that, all other things being equal, a very great number of matches may be penalised.
The subtree RRL of pages with less than 171 matches next tests for a match in the meta fields. The matter is not conclusive, but it seems to be better to have such a match (381+:7-) than not (68+:9-). In the latter case, it is better to have more than 7 matches (57+:1-) than fewer (11+:8-).
The precise numbers appearing in the test nodes - 171 matches, 14K in length - should be taken to indicate biases, weightings and trends in the Lycos search engine. They do not imply that Lycos compares those attributes with those values. We can conclude that Lycos pays most attention to the number of matches, probably with some penalty for spamming. There is some bias against long pages, possibly accidental. Lycos seems to weight words in the first heading and the meta fields highly.
7 Infoseek
The decision tree inferred for Infoseek is shown in Figure 2. Again, the first test is for at least one match and the right subtree, R, is the interesting one. Next, having at least one match in the title is better (434+:1-) than having none (4127+:131-).

Figure 2: Decision Tree for InfoSeek
If there is a match in the document but not in the title, i.e. subtree RL, it is better to have no match in the meta fields (3202+:52-) than to have any there (925+:79-). This needs to be interpreted carefully. It is consistent with Infoseek ignoring the meta fields in some circumstances, because a page with n matches in total and with one in the meta fields has n-1 matches elsewhere. It is hard to imagine a search engine penalising a page for matches in the meta fields, at least for a reasonable number of such matches. The subtree RLRLL further tests the number of matches in the meta fields and it is very bad (0+:15-) to have 12 or more. This is consistent with Infoseek's warning that it ignores meta fields having more than 6 uses of a word.
Both subtrees of RL test the total number of matches, the document length and the existence of a first heading tag in various orders so these attributes are obviously important to Infoseek.
Infoseek pays most attention to the total number of matches in a page and to a match in the title. Matches in the meta fields are important - but not too many. A proper heading increases the odds of a page being a positive. All this indicates that Infoseek takes note of the structure of a WWW page and takes anti-spamming measures.
8 Alta Vista
Figure 3 gives the best decision tree for Alta Vista. Like Lycos, the first test in the right subtree is to compare document length to 14K and it is better to be shorter (5993+:62-) than longer (612+:132-). This probably has the same explanation as for Lycos.
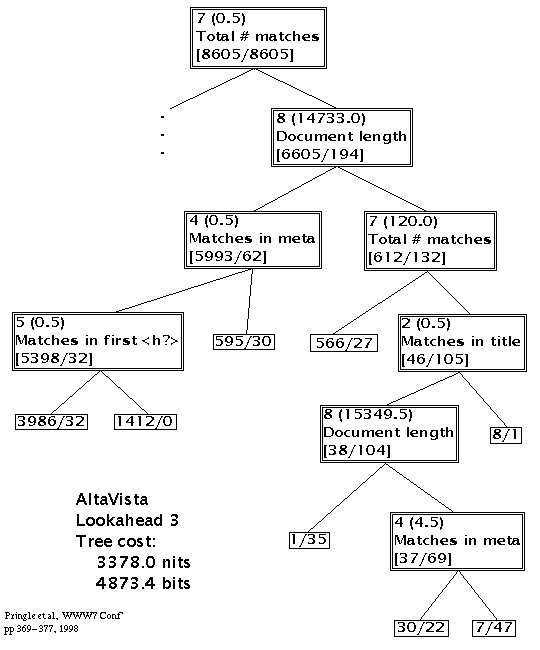
Figure 3: Decision Tree for Alta Vista
Subtree RR deals with the longer pages. Pages with fewer than 120 matches have a higher ratio of positives (566+:27-) than those with more (46+:105-) and suggests anti-spamming measures. Amongst the latter however, a match in the title seems to be a "good excuse", (8+:1-).
The subtree RLL tests for a match in the first heading and it is better to have one (1412+:0-) than not (3986+:32-). Subtree RRRLR tests for 5 or more matches in the meta and positive pages have fewer (30+:22-) rather than more (7+:47-).
Matches in headings, title and meta fields are important to Alta Vista. There is evidence that high numbers of matches in general, and in meta fields in particular, are penalised. There is a slight bias against long pages but this may be due to the way that pages are written and to some form of normalisation of word counts against document length.
9 Excite
The decision tree inferred for Excite is the most complex for any of the search engines. This is consistent with subjective impressions that Excite pays the most attention to the structure of WWW pages.
The size of the decision tree and the tests on many different attributes show that this search engine pays a great deal of attention to the structure of WWW pages.
10 Interpretations
The inference program uses information theory to direct its search for a good decision tree. A good tree gives an efficient coding of the data, in particular of the positive or negative status of a given page. It can be thought of as trying to compress the data. The tree itself is just a hypothesis and is part of the coding of the data - it is a kind of overhead. An efficient coding of decision trees is used [Wallace93] but there are a great many possible trees, some being equivalent to each other, and the search for a good one is difficult.
The inference program contains a lookahead parameter to control its search. A tree can be modified incrementally by splitting a node with a new test or by removing a test and merging the children. Possible modifications of the current best tree are tried up to the lookahead limit and the best descendant is chosen. Lookahead values of 0, 1, 2, 3 were tried for each WWW search engine. It tends to be the case that higher lookahead gives better results but this is not always the case. As it happens, lookahead 3 gave the best results for all WWW search engines by narrow margins. It might be that an even higher lookahead would give better results but this is not practical given the large data sets and the computational resources available. In any case, the good trees for a WWW search engine have similar structures. We cannot be sure that we have the best tree but it is doubtful that much more would be learned from one that was marginally better.
Generally speaking, the higher that an attribute is tested in a decision tree, the more important it is. However one should not attach great importance to two attributes being tested in one order here and another order there, unless the consequent statistics are striking.
Finding negative data for the study is problematic. We would like to have "typical" pages known to the search engines but not returned in response to queries. Instead we have had to make do with pages returned for other queries, hoping that these are not biased in some way. The decision tree program is robust to noise in the data.
11 MML, decision trees and linear regression
Two possible ways of examining the data from this paper are by inferring a decision tree of which pages do or do not make the top 200, and by using a linear regression to infer score as a function of page attributes. We have studied MML decision trees extensively in earlier sections, and now investigate linear regression [Baxter94].
Our data for this problem was obtained from creating an artificial word (which we deliberately conceal), creating several WWW pages featuring this word throughout the document in places such as the title, the meta and some such places. Seven such locations, which are the attributes, were used leading to a total of 128 pages to cover every combination of these as shown here:
- Document title.
- Meta - keywords.
- Meta - description.
- First <H1> tag.
- Early in the document body.
- Middle of the document body.
- Near the end of the document body.
The pages thus created were then submitted to the major search engines. As of the date of writing (three months after submitting the pages), Infoseek was the only search engine to have indexed a significant number of the pages, and it had only indexed 32 of them. Infoseek returns a score for each page returned as part of a search result which is a measure of "confidence" that Infoseek has that this is a good match for the search. We do not know what scale this is on so we are unsure what "irrelevant" is on the scale.
Linear regression was performed on the score as a function of the inclusion of our seven chosen document attributes. The bottom two scores of the indexed pages were 39% and 50%, which made us believe that a regression including a constant term could lead to selection bias and an inflated value of the constant term. So, we performed two regressions, one with the seven attributes alone and the other with the seven attributes and a constant term. The idea behind the former regression (without the constant term) is that the removal of the constant term constrains the regression to go through the origin and should therefore remove some of the selection bias.
Table 1 is the co-efficients from the regression with only seven attributes while Table 2 are those where the constant term was added. The standard deviation for seven attributes was 18.58 while it was only 3.19 when the constant term was added. The constant term had the value 48.19, which means that the minimum score possible with no attributes is 48.19. Comparing the co-efficients we can see that without the constant term in Table 1 the values of the constants are larger then in Table 2 as we would expect, in come cases significantly larger. Attribute 1 (document title) had the highest value in both, indicating that Infoseek pays most attention to it. It is interesting that the attributes with the largest co-efficients featured high in the tree in Figure 2.
| ||||||||||||||||
| Table 1: Co-efficients of Regression Using Seven Attributes |
| ||||||||||||||||||
| Table 2: Co-efficients of Regression Using Eight Attributes |
The real score returned by Infoseek differed from that calculated using the co-efficients found using regression by less then one standard deviation in all but twenty-five percent of the cases for the use of seven attributes, for the use of the constant as the eighth attribute, sixteen percent of cases. The order of the results based upon the calculated score did not change significantly from other pages with similar scores.
12 Conclusions
We obtained positive and negative examples of world wide web (WWW) pages returned by the popular search engines Alta Vista, Excite, Infoseek and Lycos in response to 50 typical single-word queries. For each search engine a decision tree was inferred as a model or explanation of how it decides whether or not a page is relevant, in fact in the short-list of relevant pages. A decision tree can be interpreted as an explanation of the workings of a search engine. It should not be taken as an exact model but as an indication of the features that the search engine weights heavily and in what combinations. Rules were extracted from the trees explaining, in some sense, the reason that some pages are successful in being selected. Following these rules is not a guarantee of success in future but is certainly a good guide.
The Alta Vista and Lycos search engines have the simplest decision trees which suggests that they have the simplest selection functions. Alta Vista's main claim to fame is the large size of its index and its high response speed, or its ability to handle a large number of users. It may have traded some accuracy in the calculation of relevance for speed of response.
Excite has the most complex decision tree, backing up its claim to use "advanced" techniques to rank pages.
Alta Vista and Lycos seem to penalise long pages slightly. This may be because authors use the all important keywords with a lower density in long pages.
Excite, at least, ignores the meta fields altogether as they are too easily manipulated. The other search engines show signs of penalising over-use of a keyword within these fields. Truly excessive numbers of matches - spamming - are also generally punished.
Based upon regression of attributes of pages, Infoseek appears to put most weight to the title, with the meta (both keywords and description) also having high significance and these tested high in the decision tree.
If you want your web page to stand out above the crowd for appropriate searches on several search engines the following are good tactics. Give informative title, headings, meta fields and, of course, text. Include important keywords in the title, headings and meta fields but do not use excessive repetition which will be caught out. Consider using terms in full more often than one would in normal writing, rather than using pronouns and other indirect ways of referring to subjects. It may be necessary to have different pages to attract different kinds of reader who might use different language and jargon - the novice, the expert, the technician, the end-user, etc. - but avoid spamming and do not attempt to attract search engines by deceit.
Bibliography
- J.R. Quinlan and R.L. Rivest. "Inferring decision trees using the minimum description length principle." Information and Computation, 80:227--248, 1989.
- C.S. Wallace and J.D. Patrick. "Coding decision trees." Machine Learning, 11:7--22, 1993.
- J.R. Quinlan. "C4.5: Programs for Machine Learning." Morgan Kaufmann, San Mateo, CA, 1993.
- R.A. Baxter and D.L. Dowe. "Model selection in linear regression using the MML criterion." In J.A. Storer and M.Cohn, editors, Proc. 4'th IEEE Data Compression Conference, page 498, Snowbird, Utah, March 1994. IEEE Computer Society Press, Los Alamitos, CA.
URLS
- Search Engine Watch http://calafia.com/webmasters/
- Search Engine Tutorial - Design and Promotion http://www.northernwebs.com/set/
- AltaVista Search Engine http://www.altavista.digital.com/
- Excite Search Engine http://www.excite.com/
- Infoseek Search Engine http://www.infoseek.com/
- Lycos Search Engine http://www.lycos.com/
- Magellan Search Engine http://www.mckinley.com/
- Magellan Voyeur http://voyeur.mckinley.com/cgi-bin/voyeur.cgi
- Excite Help: Getting Listed http://www.excite.com/Info/listing.html
- Infoseek Results Help http://www.infoseek.com/Help?pg=HomeHelp.html
[These were pre-google days.]